Building Toward Materials by Design in R&D
This content was originally discussed in the webinar, A Technical Framework for Materials by Design in Enterprise R&D.
A Technical Framework for Materials by Design | View the recording for this timely webinar on Materials by Design for enterprise R&D.

3 min read
.png)
Data sits at the center of modern scientific research and serves as the foundation of discovery and differentiation. However, many R&D organizations find themselves with a scarcity of high-quality, comprehensive datasets.
Why? Often they are so focused on immediate innovation that data acquisition is solely designed for answering specific, current research questions. This data is also inevitably scattered and siloed, residing across individual researcher laptops, lab instruments, software tools, and cloud drives. In addition, researchers may iterate and understand what worked and what didn’t at the time, but this full context is rarely articulated or recorded alongside the data.
As a result, when a new question arises, much of the historical data is not useful. For example:
Ultimately, this lack of usable data results in surprisingly small datasets—also known as “small data”—greatly hindering discovery and innovation since the data cannot effectively serve advanced purposes, including training robust machine learning (ML) models.
When organizations approach ML projects using conventional best practices without accounting for data scarcity from the outset, they encounter significant limitations.
When datasets are small relative to the complexity of the problem being solved, models face what’s known as the “curse of dimensionality.” Essentially, the model is asked to learn a concept that is too complex for the amount of data available. This discrepancy between model complexity and quantity of quality data creates several challenges. Models may struggle to identify reliable patterns, and any biases present in the limited dataset can be amplified rather than smoothed out.
This leads to a significant and common risk of overfitting, where the model learns the noise and specifics of the limited training data instead of the underlying general principles. Ultimately, this results in models with poor generalization capabilities, directly undermining the return on investment in AI projects and reducing confidence in new discoveries.
The path forward doesn't require compromising on your machine learning models or running more costly, time-consuming experiments. It lies in strategically incorporating other intellectual assets—mathematical and scientific theory, expert intuition, and more.
The three concepts below are key to understanding how to address data scarcity and transform small data into high-impact outcomes.
Informed Machine Learning (IML) incorporates domain knowledge and prior expertise into models to overcome data limitations far more effectively than simply collecting more data.
As shown in Figure 1, IML integrates existing domain expert knowledge, world knowledge (physical laws), and scientific knowledge directly into the ML process. This integration allows models to learn from both experimental data and established knowledge, leading to faster training, higher accuracy, and dramatically improved generalization with less data, which is critical for complex tasks like scientific discovery.
IML offers strategic advantage by delivering trustworthy, explainable, and scientifically consistent predictions, enabling accelerated decision-making and innovation in R&D and operational environments.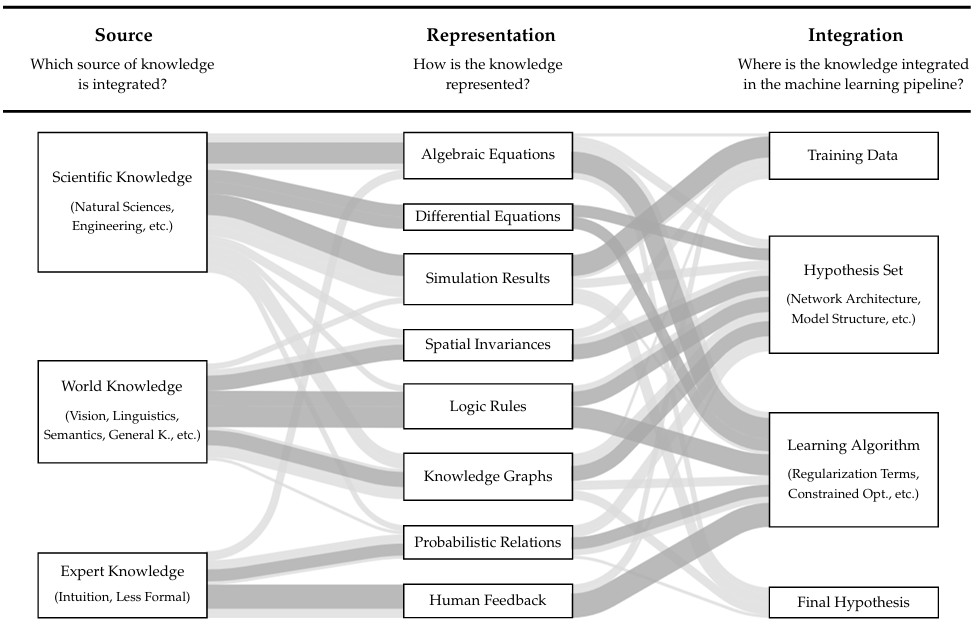
In an environment defined by small datasets, every prediction carries a degree of uncertainty. Optimal Uncertainty Quantification (OUQ) is an advanced mathematical method that measures the impact of lacking knowledge, transforming uncertainty into actionable intelligence for decision-makers. OUQ has been applied across domains, as illustrated in Figure 2, where lack of knowledge can be consequential and costly to assess the impact of uncertainty and alleviate it.
With OUQ, you receive best-case, expected-case, and worst-case scenarios, allowing your team to:
This capability delivers the trustworthy, explainable predictions essential for high-stakes R&D decision-making.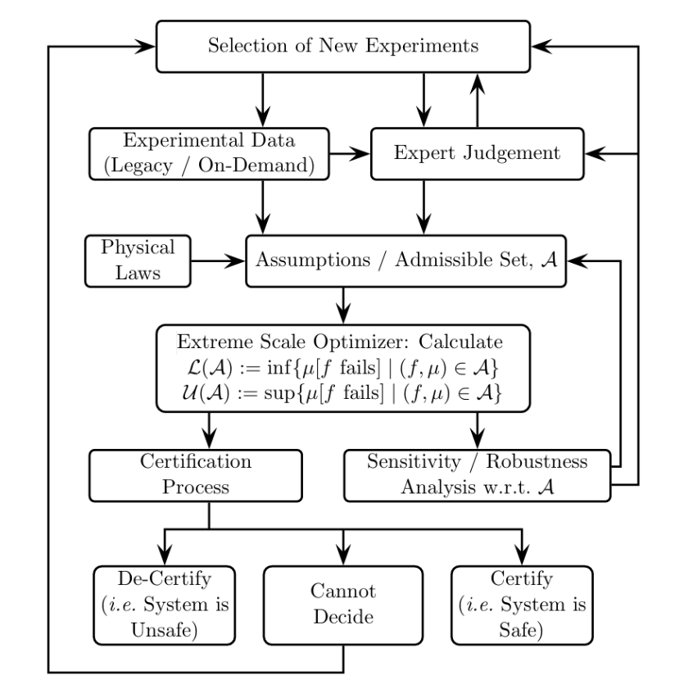
Figure 2: Optimal Uncertainty Quantification Loop
Source: Optimal Uncertainty Quantification. SIAM Review, Volume 55, 2013.
Given experiments are expensive, you cannot afford to waste a single one. Historically, questions like “what data to collect” or “what experiment to run next” have been answered through intuition or ad hoc processes. While more systematic approaches like Design of Experiment (DoE) and techniques like Bayesian Experimental Design have been around for a while, they are not used at scale. However, recent advancements in AI and Optimization theory have completely transformed this landscape.
By using AI surrogates and active learning techniques (Figure 3), researchers are reporting reductions in their data needs by orders of magnitude. This is accomplished by online-learning of the response surface using AI surrogates and a novel active learning technique that recovers the extremal points of the response surface. This novel approach directly specifies which data points to collect or experiments to run and in turn maximally improve the Experimental Design objectives. The result is an AI system that guides data collection so every experiment counts.
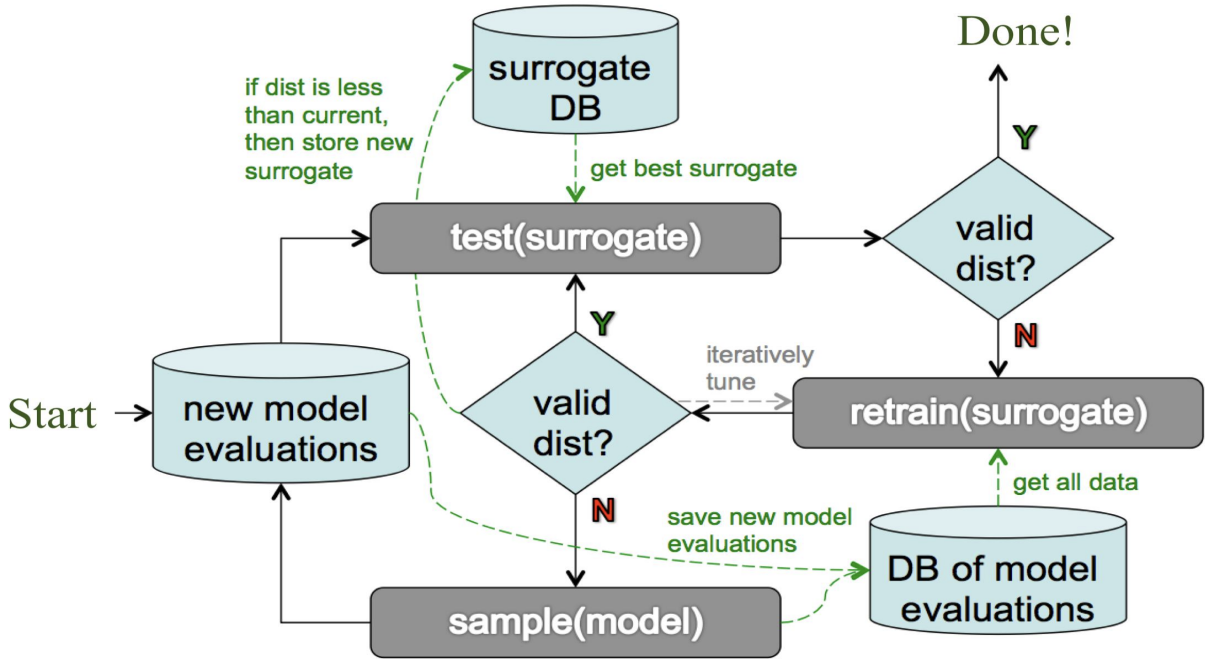
Figure 3: Schematic for Automated Generation of Inexpensive Surrogates for Complex Systems
Source: Efficient Learning of Accurate Surrogates for Simulations of Complex Systems. Nature Machine Intelligence, Volume 6, 2024.
The Path Forward
The small data problem in scientific R&D is solvable. By embracing new ideas and concepts, such as the three above, R&D leaders can move beyond the assumption that "more data is the only answer." Laboratories willing to adopt these strategies in their models will see faster innovation cycles, reduced experimental costs, and the ability to thrive in an increasingly competitive landscape where speed to market determines success.
Small datasets don’t have to limit your research and development progress.
Enthought specializes in purpose-built AI/ML scientific solutions for enterprise R&D. Let’s discuss your specific challenges and how we can help. Contact us.

This content was originally discussed in the webinar, A Technical Framework for Materials by Design in Enterprise R&D.

This article was originally published on Forbes.

In 2024, we published The Top 10 AI Concepts Every Scientific R&D Leader Should Know, during the rise of generative AI and LLMs. A lot has changed...