The rise of ChatGPT and BARD based on large language models (LLMs) has shown the potential of generative models to assist with a variety of tasks. However, we want to highlight how generative models can be used in many more areas than just language generation, with one particularly promising area: molecule generation for chemical product development.
Conventional discovery of new molecules is often done through expensive and time-consuming trial-and-error approaches. This means that scientists may miss many potential candidates. Instead, generative models can be used to explore molecular spaces and discover molecules that have not been synthesized in the lab or even theorized in simulations. These novel molecules could therefore be patented.
Generative Models: A New Method for Molecule Discovery
In the generative models, an important aspect is the molecules representation, with some of the more common representations being molecular graphs, SMILES, and SELFIES. SELFIES have the additional advantage that every SELFIE string is a valid molecule. This allows for SELFIES to be mutated or generated from latent space and still represent a valid molecule. These molecule representations are the input to the generative model, with some of the more popular generative models being variational autoencoders (VAEs), generative adversarial networks (GANs), and normalizing flow.
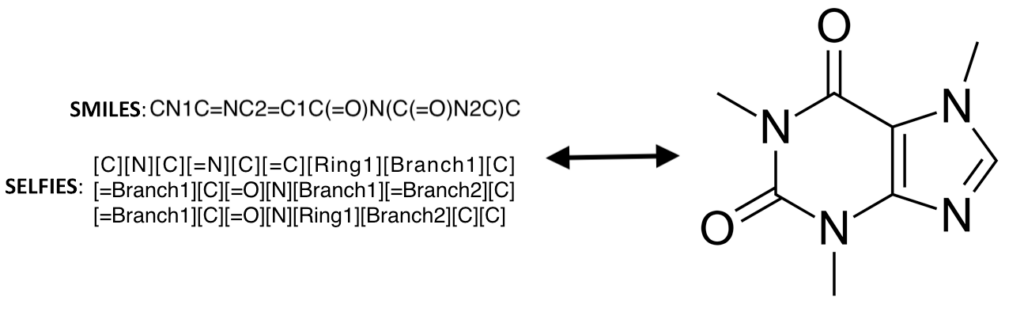
SELFIES, SMILES, and molecular graph representations of the caffeine molecule
These generative models are unsupervised models, which means they don’t require knowing the properties of the molecules (i.e. unlabeled). The models can therefore be trained on large databases of molecules even if they don’t have the properties of interest. For example, the models can be trained on large existing open-source molecule databases, such as ChEMBL or QM9, which significantly reduces the cost and complexity of data collection.
Challenges and Solutions for Generation Models
However, there are some problems with this approach. For example, the generated molecules might not satisfy all property requirements, might be difficult and costly to synthesize, or may not meet other business requirements like manufacturability. This can be especially difficult when there are multiple business requirements. Fortunately, there are several different solutions to this.
One option is to use a funnel or filter approach. In this approach, many molecules are generated and then each molecule is checked to see if it passes certain requirements. If it doesn’t pass the requirement, the molecule is removed from the potential molecules. Then the remaining molecules will be tested on the next filter until all filters have been tested. These filters can be a simulation, experiment, or even a machine learning (ML) model. While this approach is rather simple, there are some advantages to it. For one, cheaper filters can be used first to reduce the number of candidate molecules, reducing the overall cost of discovering a new molecule. The cheap filters are any test that can be done quickly and at a low cost for many molecules, such as a ML model or simulation. However, this approach can still be very expensive if the filters are expensive, with some lab experiments and simulations being costly and time-consuming to run.
In the case where there are no robust and cheap models, another approach is to guide the exploration of these novel regions of chemical space using methods such as Bayesian optimization or active learning. Bayesian optimization would be used to find the best molecule in the chemical space, whereas active learning would be used to create accurate and robust models. The active learning approach would also be useful for creating an ML model which could be used as a cheap filter in the filter approach.
If the generative model represents the molecules in a latent space, such as in a VAE and normalizing flow, one could instead train a machine learning model to predict the given properties from the latent space. The problem can then be treated as an inverse design problem, where promising candidates are optimized in the latent space. Then the latent space representation can be transformed back into a molecule for further exploration. These methods allow for gradient-based techniques to be used to find the best molecule.
A different approach is to instead train your generative model on molecules that are already known to pass your requirements, such as synthesis cost and manufacturability. So instead of learning the distributions of all molecules, the generative model will instead learn the distribution of molecules that pass your requirements. The new generative model would then generate molecules that pass your requirements. However, this requires the data to be labeled, essentially converting the problem from an unsupervised task to a supervised one. To reduce the data requirements, one can start with a pre-trained generative model and then tune the model. The major advantage of this approach is that the molecules are more likely to pass your requirements, so fewer molecules have to be generated and tested.
Staying Ahead of the Curve
While there are several important factors to consider when utilizing these generative models for molecules, these technologies are becoming mature enough such that valuable and industrially viable materials informatics software solutions can now be built. Integrating generative methods into your workflows can help quickly identify promising candidates that meet all of your design requirements since the generative models for molecules can be thought of as giving you access to an infinite database of promising new molecules. Innovation leaders are investing in learning how to leverage these tools in their R&D teams to give them a competitive advantage, especially when pursuing new markets with high growth potential and room for major chemical innovation.
Watch Webinar-on-Demand: Materials Informatics for Product Development: Deliver Big with Small Data
Related Content
Digital Transformation vs. Digital Enhancement: A Starting Decision Framework for Technology Initiatives in R&D
Leveraging advanced technology like generative AI through digital transformation (not digital enhancement) is how to get the biggest returns in scientific R&D.
Digital Transformation in Practice
There is much more to digital transformation than technology, and a holistic strategy is crucial for the journey.
Leveraging AI for More Efficient Research in BioPharma
In the rapidly-evolving landscape of drug discovery and development, traditional approaches to R&D in biopharma are no longer sufficient. Artificial intelligence (AI) continues to be a...
Utilizing LLMs Today in Industrial Materials and Chemical R&D
Leveraging large language models (LLMs) in materials science and chemical R&D isn't just a speculative venture for some AI future. There are two primary use...
Top 10 AI Concepts Every Scientific R&D Leader Should Know
R&D leaders and scientists need a working understanding of key AI concepts so they can more effectively develop future-forward data strategies and lead the charge...
Why A Data Fabric is Essential for Modern R&D
Scattered and siloed data is one of the top challenges slowing down scientific discovery and innovation today. What every R&D organization needs is a data...
Jupyter AI Magics Are Not ✨Magic✨
It doesn’t take ✨magic✨ to integrate ChatGPT into your Jupyter workflow. Integrating ChatGPT into your Jupyter workflow doesn’t have to be magic. New tools are…
Top 5 Takeaways from the American Chemical Society (ACS) 2023 Fall Meeting: R&D Data, Generative AI and More
By Mike Heiber, Ph.D., Materials Informatics Manager Enthought, Materials Science Solutions The American Chemical Society (ACS) is a premier scientific organization with members all over…
Real Scientists Make Their Own Tools
There’s a long history of scientists who built new tools to enable their discoveries. Tycho Brahe built a quadrant that allowed him to observe the…
How IT Contributes to Successful Science
With the increasing importance of AI and machine learning in science and engineering, it is critical that the leadership of R&D and IT groups at...